
最近看到掘金、前端公众号好多 ES2020 的文章,想说一句:放开我,我还学得动!
先问大家一句,日常项目开发中你能离开 ES6 吗?
一、前言
对于前端同学来说,编译器可能适合神奇的魔盒🎁,表面普通,但常常给我们惊喜。
编译器,顾名思义,用来编译,编译什么呢?当然是编译代码咯🌹。
其实我们也经常接触到编译器的使用场景:
- React 中 JSX 转换成 JS 代码;
- 通过 Babel 将 ES6 及以上规范的代码转换成 ES5 代码;
- 通过各种 Loader 将 Less / Scss 代码转换成浏览器支持的 CSS 代码;
- 将 TypeScript 转换为 JavaScript 代码。
- and so on…
使用场景非常之多,我的双手都数不过来了。😄
虽然现在社区已经有非常多工具能为我们完成上述工作,但了解一些编译原理是很有必要的。接下来进入本文主题:200行JS代码,带你实现代码编译器。
二、编译器介绍
2.1 程序运行方式
现代程序主要有两种编译模式:静态编译和动态解释。推荐一篇文章《Angular 2 JIT vs AOT》介绍得非常详细。
静态编译
简称 AOT(Ahead-Of-Time)即 提前编译 ,静态编译的程序会在执行前,会使用指定编译器,将全部代码编译成机器码。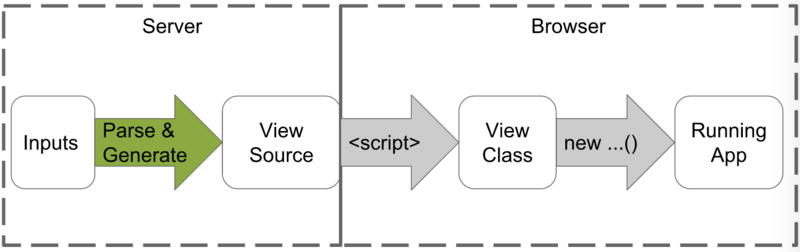
(图片来自:https://segmentfault.com/a/1190000008739157)
在 Angular 的 AOT 编译模式开发流程如下:
- 使用 TypeScript 开发 Angular 应用
- 运行 ngc 编译应用程序
- 使用 Angular Compiler 编译模板,一般输出 TypeScript 代码
- 运行 tsc 编译 TypeScript 代码
- 使用 Webpack 或 Gulp 等其他工具构建项目,如代码压缩、合并等
- 部署应用
动态解释
简称 JIT(Just-In-Time)即 即时编译 ,动态解释的程序会使用指定解释器,一边编译一边执行程序。 (图片来自:https://segmentfault.com/a/1190000008739157)
(图片来自:https://segmentfault.com/a/1190000008739157)
在 Angular 的 JIT 编译模式开发流程如下:
- 使用 TypeScript 开发 Angular 应用
- 运行 tsc 编译 TypeScript 代码
- 使用 Webpack 或 Gulp 等其他工具构建项目,如代码压缩、合并等
- 部署应用
AOT vs JIT
AOT 编译流程: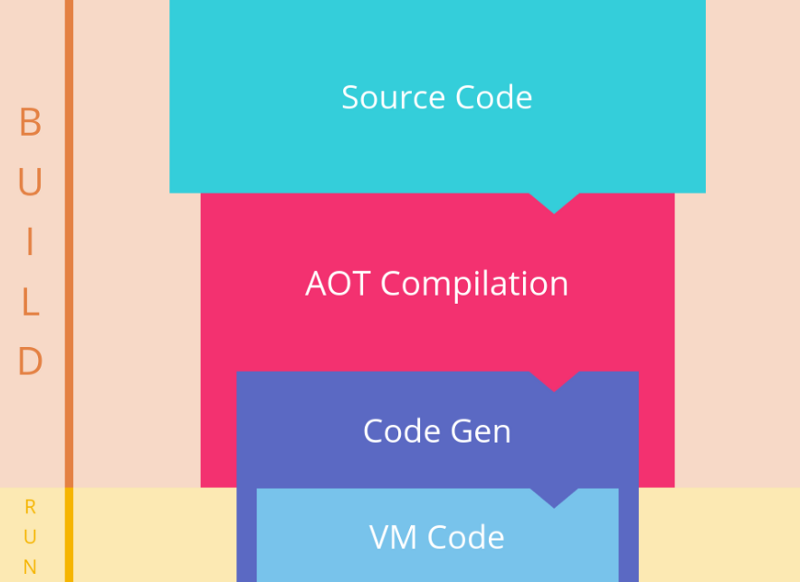 (图片来自:https://segmentfault.com/a/1190000008739157)
(图片来自:https://segmentfault.com/a/1190000008739157)
JIT 编译流程: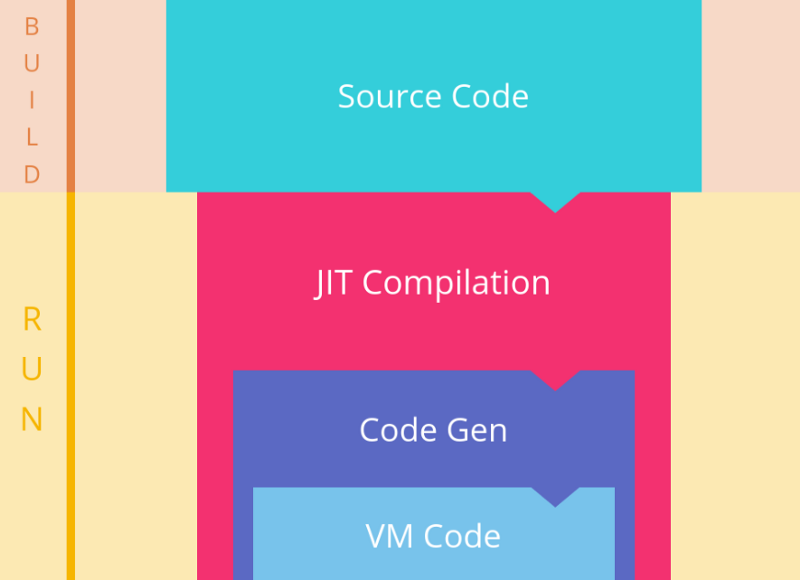 (图片来自:https://segmentfault.com/a/1190000008739157)
(图片来自:https://segmentfault.com/a/1190000008739157)
| 特性 | AOT | JIT |
|---|---|---|
| 编译平台 | (Server) 服务器 | (Browser) 浏览器 |
| 编译时机 | Build (构建阶段) | Runtime (运行时) |
| 包大小 | 较小 | 较大 |
| 执行性能 | 更好 | - |
| 启动时间 | 更短 | - |
除此之外 AOT 还有以下优点:
- 在客户端我们不需要导入体积庞大的 angular 编译器,这样可以减少我们 JS 脚本库的大小
- 使用 AOT 编译后的应用,不再包含任何 HTML 片段,取而代之的是编译生成的 TypeScript 代码,这样的话 TypeScript 编译器就能提前发现错误。总而言之,采用 AOT 编译模式,我们的模板是类型安全的。
2.2 现代编译器工作流程
摘抄维基百科中对 编译器工作流程介绍:
一个现代编译器的主要工作流程如下:
源代码(source code)→ 预处理器(preprocessor)→ 编译器(compiler)→ 汇编程序(assembler)→ 目标代码(object code)→ 链接器(linker)→ 可执行文件(executables),最后打包好的文件就可以给电脑去判读运行了。

这里更强调了编译器的作用:将原始程序作为输入,翻译产生目标语言的等价程序。
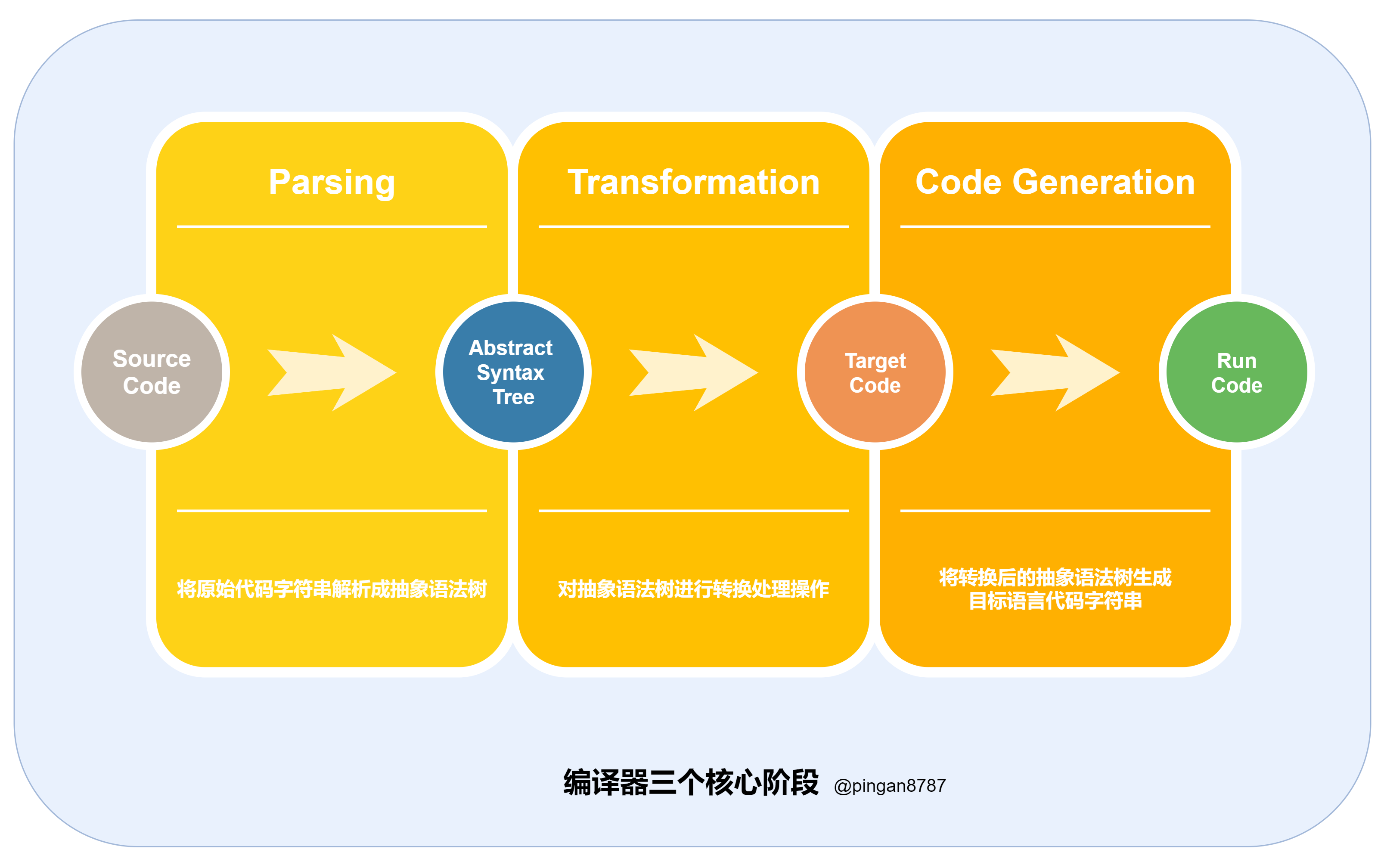
目前绝大多数现代编译器工作流程基本类似,包括三个核心阶段:
- 解析(_Parsing_) :通过词法分析和语法分析,将原始代码字符串解析成抽象语法树(Abstract Syntax Tree);
- 转换(_Transformation_):对抽象语法树进行转换处理操作;
- 生成代码(_Code Generation_):将转换之后的 AST 对象生成目标语言代码字符串。
三、编译器实现
本文将通过 The Super Tiny Compiler 源码解读,学习如何实现一个轻量编译器,最终实现将下面原始代码字符串(Lisp 风格的函数调用)编译成 JavaScript 可执行的代码。
| Lisp 风格(编译前) | JavaScript 风格(编译后) | |
|---|---|---|
| 2 + 2 | (add 2 2) | add(2, 2) |
| 4 - 2 | (subtract 4 2) | subtract(4, 2) |
| 2 + (4 - 2) | (add 2 (subtract 4 2)) | add(2, subtract(4, 2)) |
话说 The Super Tiny Compiler 号称可能是有史以来最小的编译器,并且其作者 James Kyle 也是 Babel 活跃维护者之一。
让我们开始吧~
3.1 The Super Tiny Compiler 工作流程
现在对照前面编译器的三个核心阶段,了解下 The Super Tiny Compiler 编译器核心工作流程: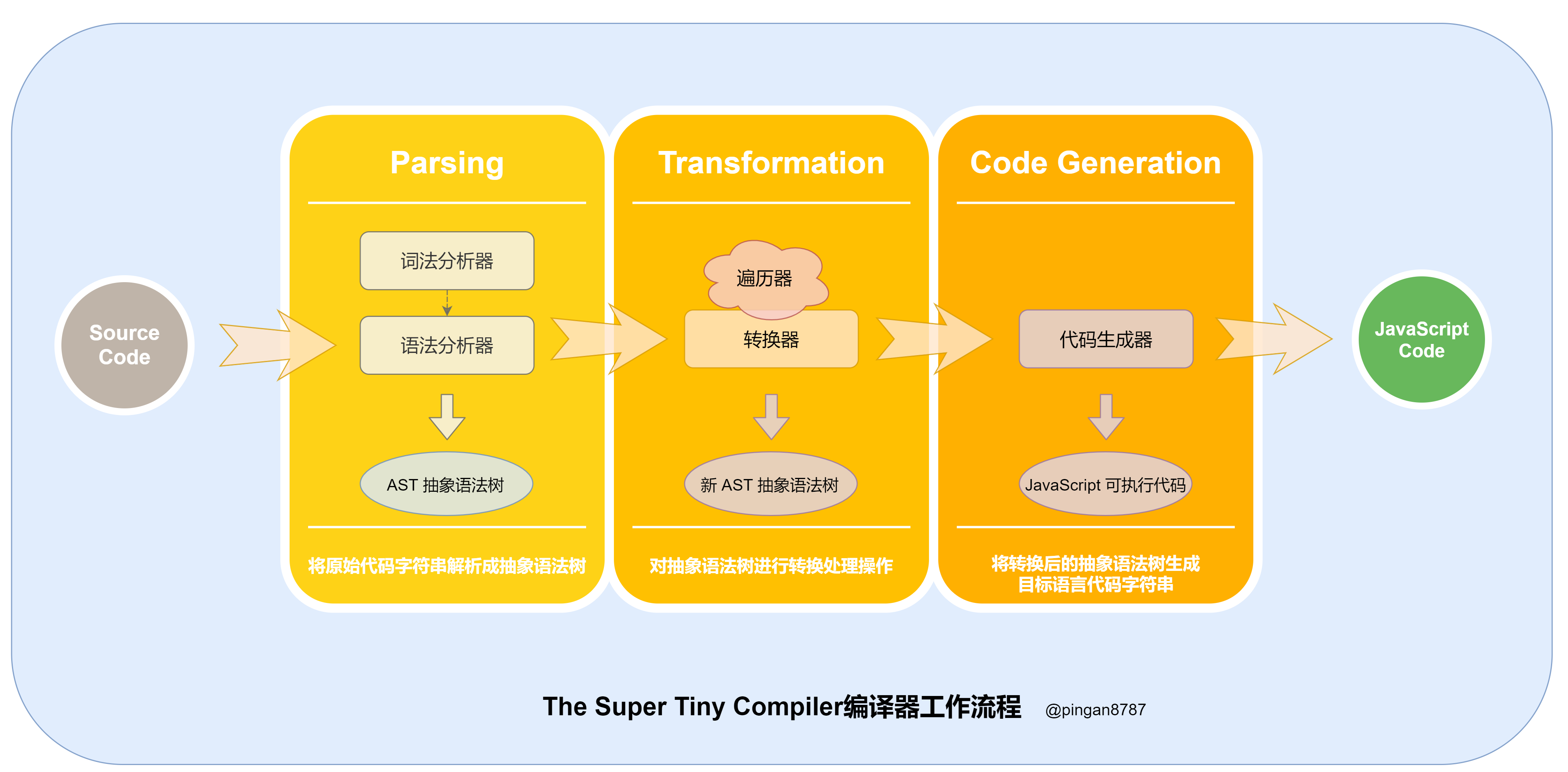
图中详细流程如下:
- 执行入口函数,输入原始代码字符串作为参数;
1 | // 原始代码字符串 |
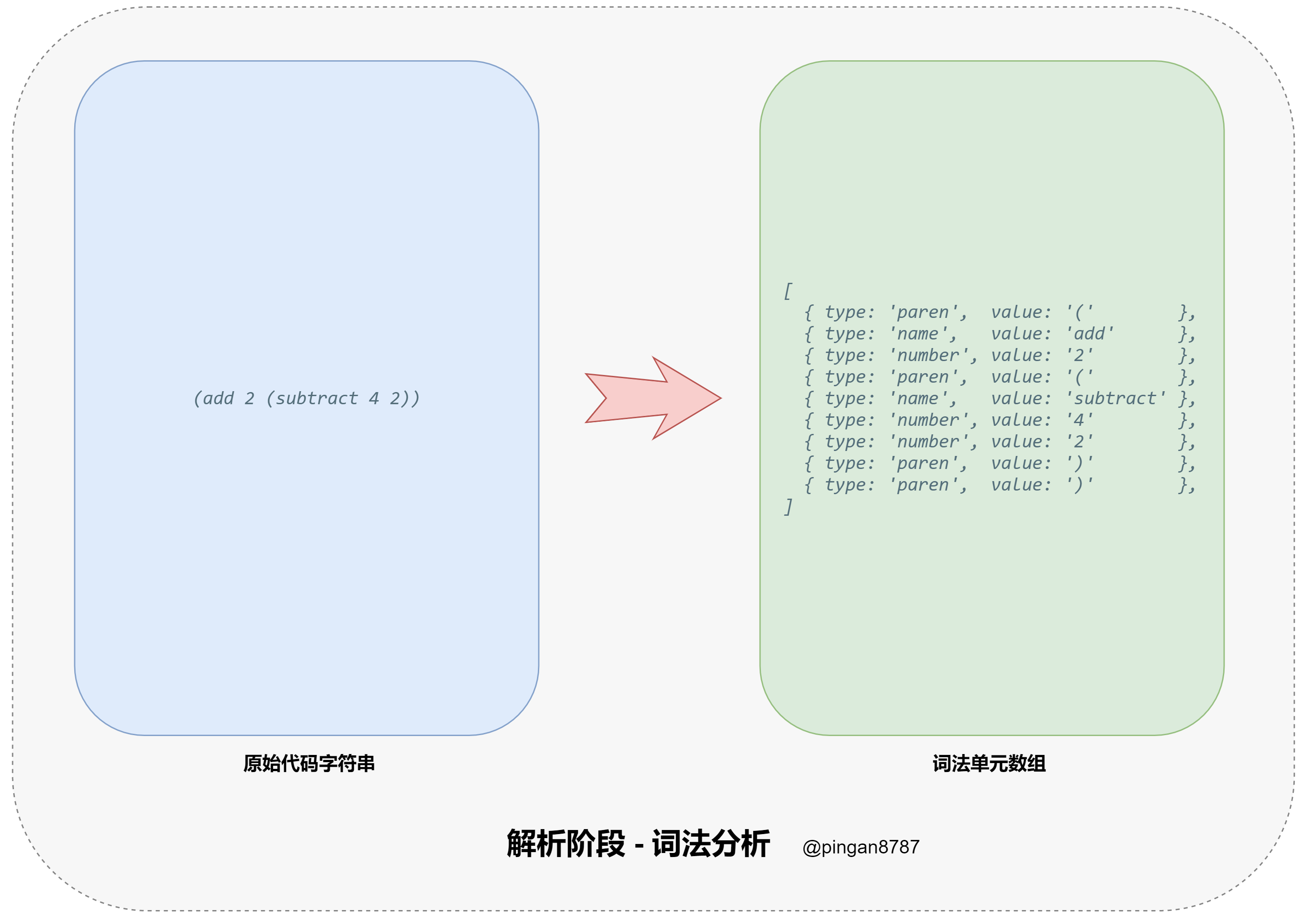
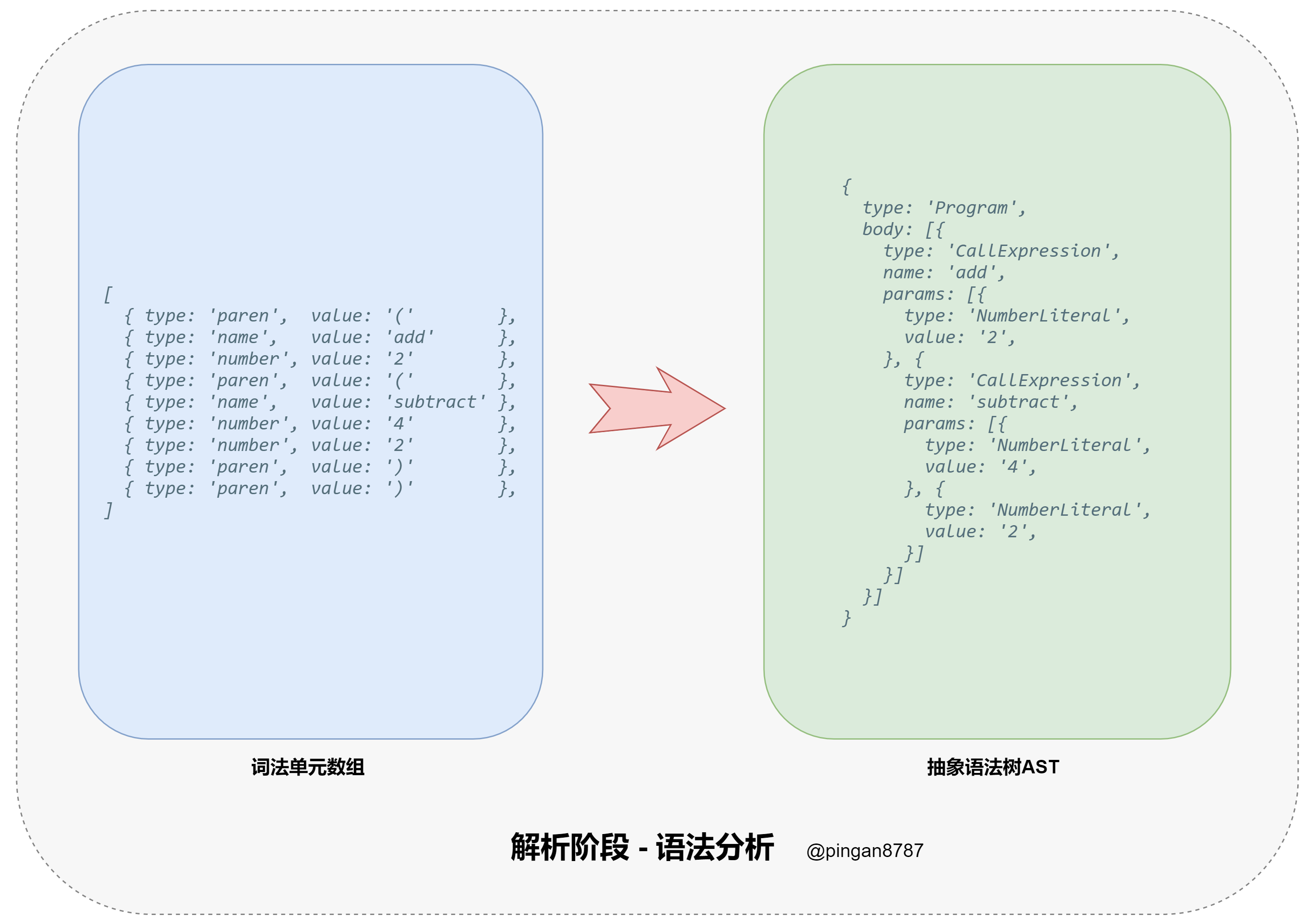
- 进入解析阶段(Parsing),原始代码字符串通过词法分析器(Tokenizer)转换为词法单元数组,然后再通过 语法分析器(Parser)将词法单元数组转换为抽象语法树(Abstract Syntax Tree 简称 AST),并返回;
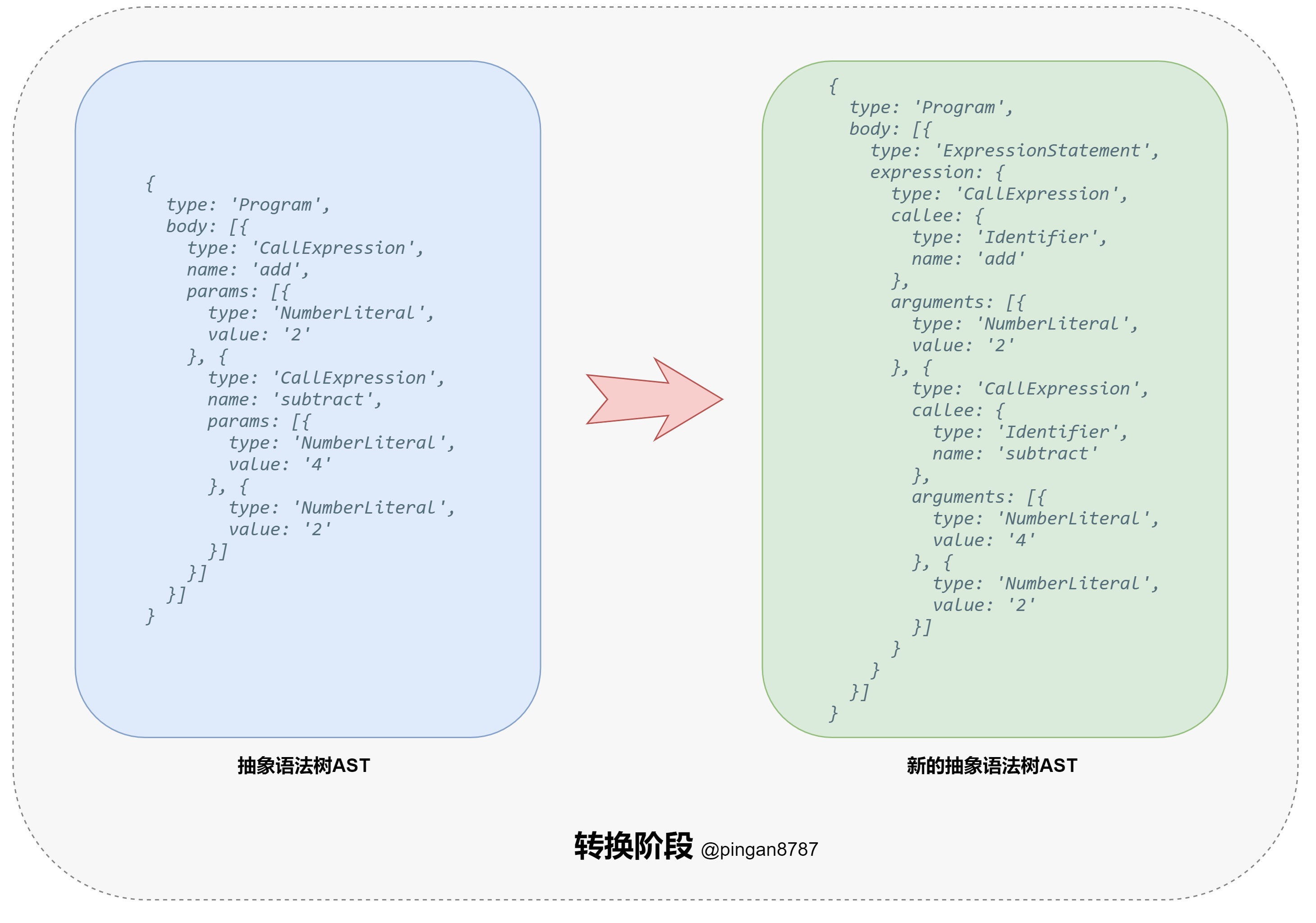
- 进入转换阶段(Transformation),将上一步生成的 AST 对象 导入转换器(Transformer),通过转换器中的遍历器(Traverser),将代码转换为我们所需的新的 AST 对象;
- 进入代码生成阶段(Code Generation),将上一步返回的新 AST 对象通过代码生成器(CodeGenerator),转换成 JavaScript Code;
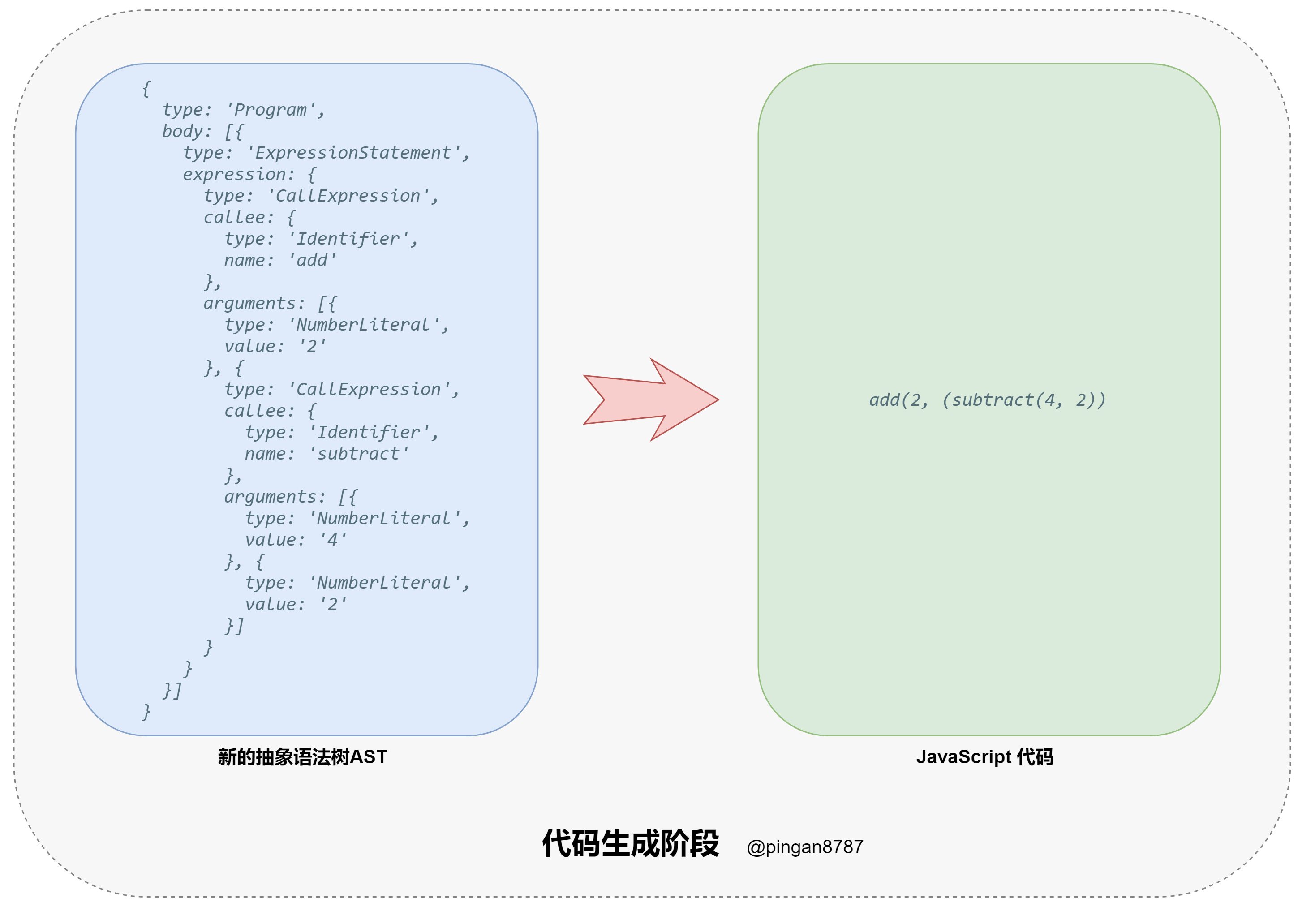
- 代码编译结束,返回 JavaScript Code。

上述流程看完后可能一脸懵逼,不过没事,请保持头脑清醒,先有个整个流程的印象,接下来我们开始阅读代码:
3.2 入口方法
首先定义一个入口方法 compiler ,接收原始代码字符串作为参数,返回最终 JavaScript Code:
1 | // 编译器入口方法 参数:原始代码字符串 input |
3.3 解析阶段
在解析阶段中,我们定义词法分析器方法 tokenizer 和语法分析器方法 parser 然后分别实现:
1 | // 词法分析器 参数:原始代码字符串 input |
词法分析器
词法分析器方法 tokenizer 的主要任务:遍历整个原始代码字符串,将原始代码字符串转换为词法单元数组(tokens),并返回。
在遍历过程中,匹配每种字符并处理成词法单元压入词法单元数组,如当匹配到左括号( ( )时,将往词法单元数组(tokens)压入一个词法单元对象({type: 'paren', value:'('})。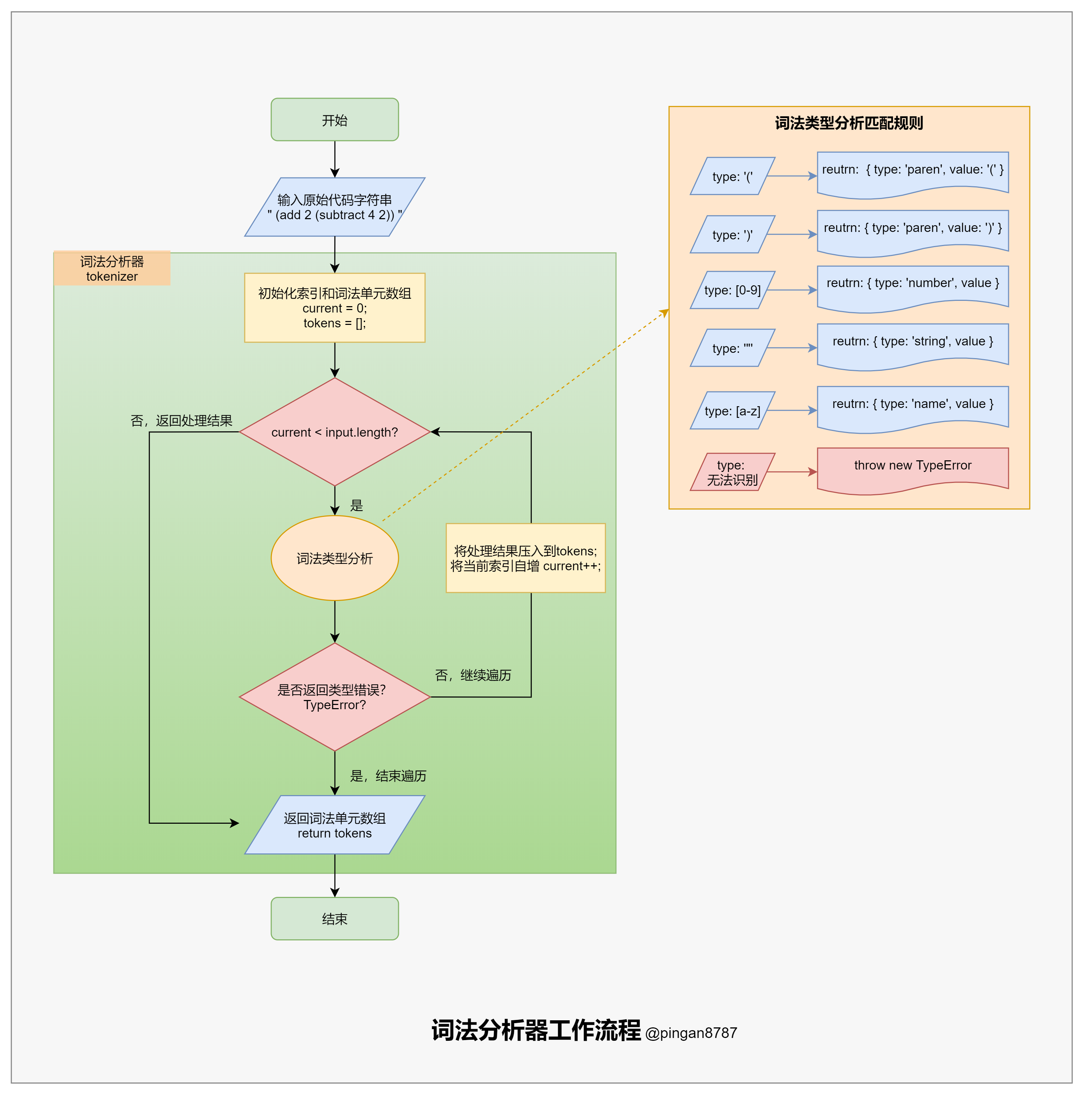
1 | // 词法分析器 参数:原始代码字符串 input |
语法分析器
语法分析器方法 parser 的主要任务:将词法分析器返回的词法单元数组,转换为能够描述语法成分及其关系的中间形式(抽象语法树 AST)。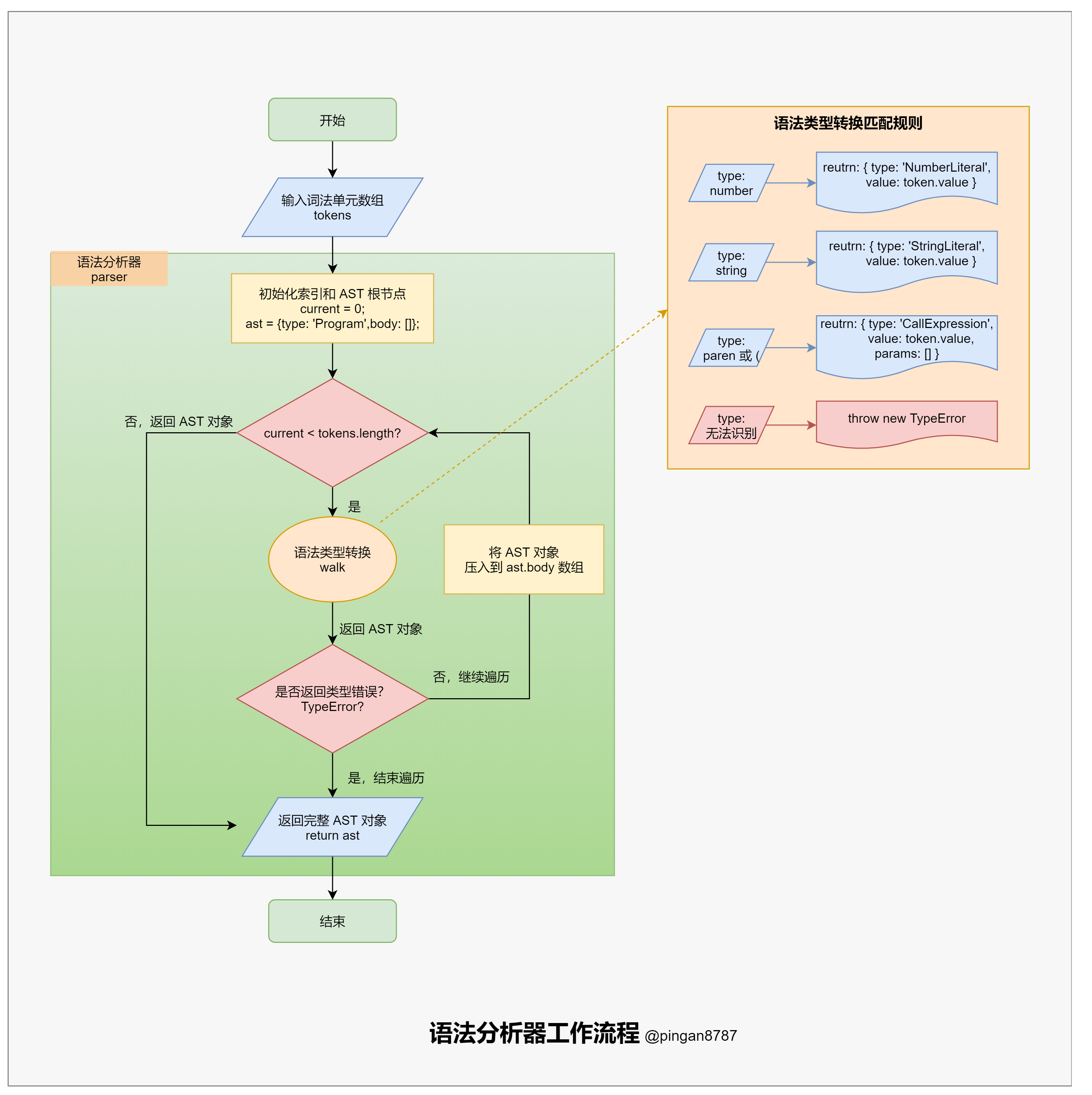
1 | // 语法分析器 参数:词法单元数组tokens |
3.4 转换阶段
在转换阶段中,定义了转换器 transformer 函数,使用词法分析器返回的 LISP 的 AST 对象作为参数,将 AST 对象转换成一个新的 AST 对象。
为了方便代码组织,我们定义一个遍历器 traverser 方法,用来处理每一个节点的操作。
1 | // 遍历器 参数:ast 和 visitor |
在看遍历器 traverser 方法时,建议结合下面介绍的转换器 transformer 方法阅读:
1 | // 转化器,参数:ast |
重要一点,这里通过 _context 引用来维护新旧 AST 对象,管理方便,避免污染旧 AST 对象。
3.5 代码生成
接下来到了最后一步,我们定义代码生成器 codeGenerator 方法,通过递归,将新的 AST 对象代码转换成 JavaScript 可执行代码字符串。
1 | // 代码生成器 参数:新 AST 对象 |
3.6 编译器测试
截止上一步,我们完成简易编译器的代码开发。接下来通过前面原始需求的代码,测试编译器效果如何:
1 | const add = (a, b) => a + b; |
3.7 工作流程小结
总结 The Super Tiny Compiler 编译器整个工作流程:
1、input => tokenizer => tokens
2、tokens => parser => ast
3、ast => transformer => newAst
4、newAst => generator => output
其实多数编译器的工作流程都大致相同: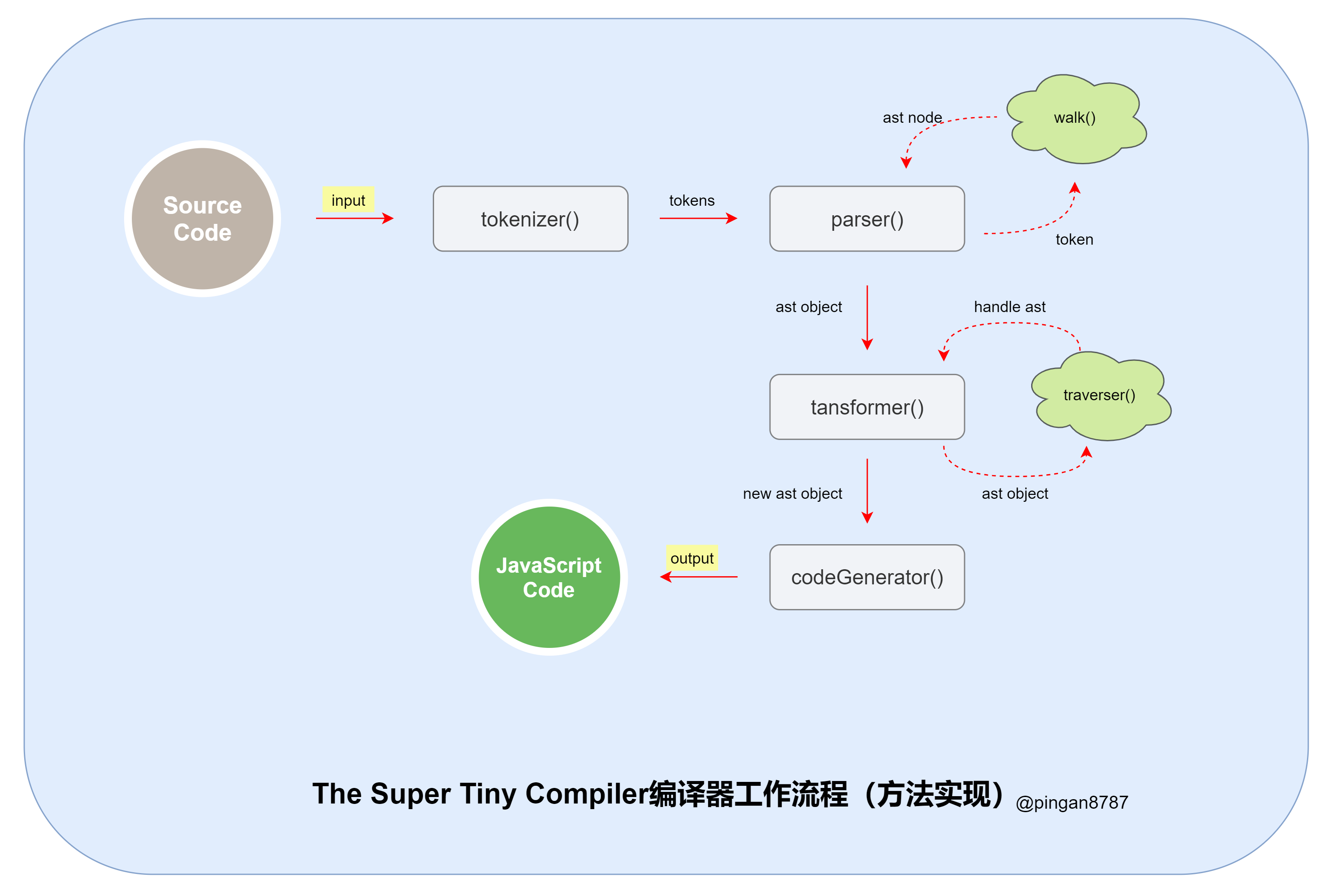
四、手写 Webpack 编译器
根据之前介绍的 The Super Tiny Compiler编译器核心工作流程,再来手写 Webpack 的编译器,会让你有种众享丝滑的感觉~
话说,有些面试官喜欢问这个呢。当然,手写一遍能让我们更了解 Webpack 的构建流程,这个章节我们简要介绍一下。
4.1 Webpack 构建流程分析
从启动构建到输出结果一系列过程:
- 初始化参数
解析 Webpack 配置参数,合并 Shell 传入和 webpack.config.js 文件配置的参数,形成最后的配置结果。
- 开始编译
上一步得到的参数初始化 compiler 对象,注册所有配置的插件,插件监听 Webpack 构建生命周期的事件节点,做出相应的反应,执行对象的 run 方法开始执行编译。
- 确定入口
从配置的 entry 入口,开始解析文件构建 AST 语法树,找出依赖,递归下去。
- 编译模块
递归中根据文件类型和 loader 配置,调用所有配置的 loader 对文件进行转换,再找出该模块依赖的模块,再递归本步骤直到所有入口依赖的文件都经过了本步骤的处理。
- 完成模块编译并输出
递归完事后,得到每个文件结果,包含每个模块以及他们之间的依赖关系,根据 entry 配置生成代码块 chunk 。
- 输出完成
输出所有的 chunk 到文件系统。
注意:在构建生命周期中有一系列插件在做合适的时机做合适事情,比如 UglifyPlugin 会在 loader 转换递归完对结果使用 UglifyJs 压缩覆盖之前的结果。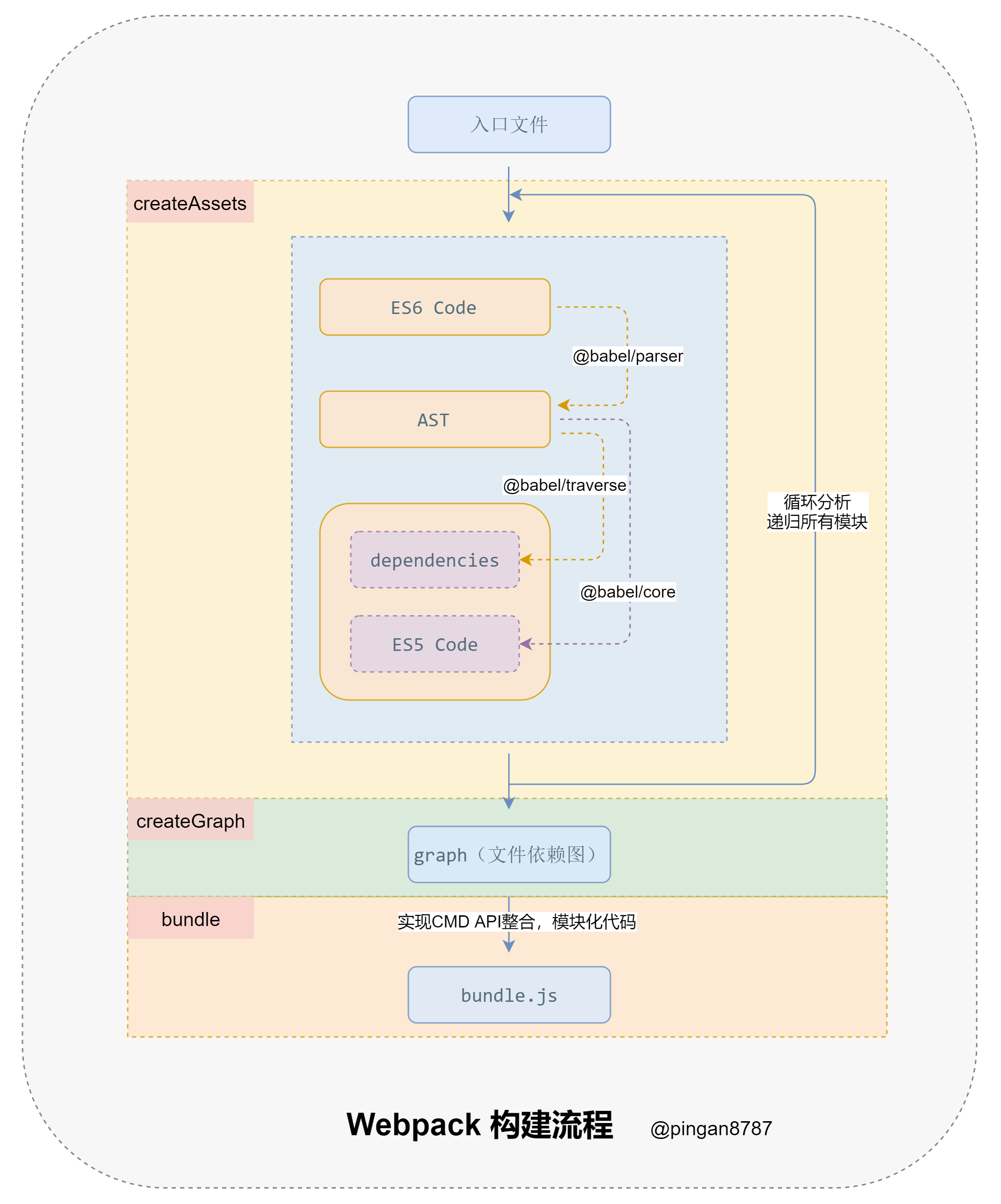
4.2 代码实现
手写 Webpack 需要实现以下三个核心方法:
createAssets: 收集和处理文件的代码;createGraph:根据入口文件,返回所有文件依赖图;bundle: 根据依赖图整个代码并输出;
1. createAssets
1 | function createAssets(filename){ |
2. createGraph
1 | function createGraph(entry) { |
3. bunlde
1 | function bundle(graph) { |
五、总结
本文从编译器概念和基本工作流程开始介绍,然后通过 The Super Tiny Compiler 译器源码,详细介绍核心工作流程实现,包括词法分析器、语法分析器、遍历器和转换器的基本实现,最后通过代码生成器,将各个阶段代码结合起来,实现了这个号称可能是有史以来最小的编译器。
本文也简要介绍了手写 Webpack 的实现,需要读者自行完善和深入哟!
是不是觉得很神奇~
当然通过本文学习,也仅仅是编译器相关知识的边山一脚,要学的知识还有非常多,不过好的开头,更能促进我们学习动力。加油!
最后,文中介绍到的代码,我存放在 Github 上:
六、参考资料
关于我
| Author | 王平安 |
|---|---|
| pingan8787@qq.com | |
| 博 客 | www.pingan8787.com |
| 微 信 | pingan8787 |
| 每日文章推荐 | https://github.com/pingan8787/Leo_Reading/issues |
| ES小册 | js.pingan8787.com |