| Author | 王平安 |
|---|---|
| pingan8787@qq.com | |
| 博 客 | www.pingan8787.com |
| 微 信 | pingan8787 |
| 每日文章 | https://0x9.me/KMrv3 |
1.引言
最近笔者和小伙伴在研究Vue SSR,但是市面上充斥了太多的从0到1的文章,对大家理解这其中的原理帮助并不是很大,因此,本文将从 Vue SSR的构建流程、运行流程、SSR的特点和利弊 这几方面对Vue SSR有一个较为详细的介绍。最后还将附上一个笔者实现的 去除Vue全家桶的Demo案例 。
2.剖析构建流程
首先我们镇上一张官网给出的构建图: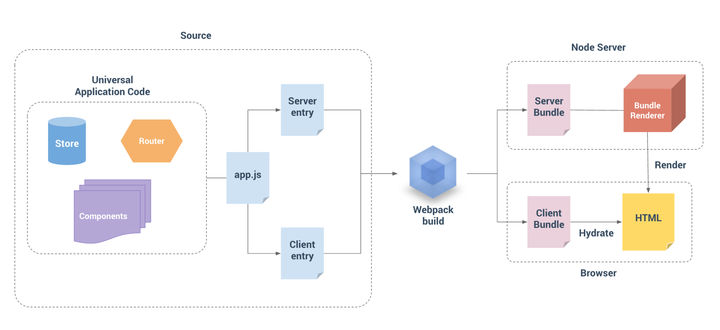
app.js入口文件
app.js 是我们的通用entry,它的作用就是构建一个Vue的实例以供服务端和客户端使用,注意一下,在纯客户端的程序中我们的app.js将会挂载实例到dom中,而在ssr中这一部分的功能放到了Client entry中去做了。
两个entry
接下里我们来看Client entry和Server entry,这两者分别是客户端的入口和服务端的入口。Client entry的功能很简单,就是挂载我们的Vue实例到指定的dom元素上;Server entry是一个使用export导出的函数。主要负责调用组件内定义的获取数据的方法,获取到SSR渲染所需数据,并存储到上下文环境中。这个函数会在每一次的渲染中重复的调用。
webpack打包构建
然后我们的服务端代码和客户端代码通过webpack分别打包,生成Server Bundle和Client Bundle,前者会运行在服务器上通过node生成预渲染的HTML字符串,发送到我们的客户端以便完成初始化渲染;而客户端bundle就自由了,初始化渲染完全不依赖它了。客户端拿到服务端返回的HTML字符串后,会去“激活”这些静态HTML,是其变成由Vue动态管理的DOM,以便响应后续数据的变化。
3.剖析运行流程
到这里我们该谈谈ssr的程序是怎么跑起来的了。首先我们得去构建一个vue的实例,也就是我们前面构建流程中说到的app.js做的事情,但是这里不同于传统的客户端渲染的程序,我们需要用一个工厂函数去封装它,以便每一个用户的请求都能够返回一个新的实例,也就是官网说到的避免交叉污染了。
然后我们可以暂时移步到服务端的entry中了,这里要做的就是拿到当前路由匹配的组件,调用组件里定义的一个方法(官网取名叫asyncData)拿到初始化渲染的数据,而这个方法要做的也很简单,就是去调用我们vuex store中的方法去异步获取数据。
接下来node服务器如期启动了,跑的是我们刚写好的服务端entry里的函数。在这里还要做的就是将我们刚刚构建好的Vue实例渲染成HTML字符串,然后将拿到的数据混入我们的HTML字符串中,最后发送到我们客户端。
打开浏览器的network,我们看到了初始化渲染的HTML,并且是我们想要初始化的结构,且完全不依赖于客户端的js文件了。再仔细研究研究,里面有初始化的dom结构,有css,还有一个script标签。script标签里把我们在服务端entry拿到的数据挂载了window上。原来只是一个纯静态的HTML页面啊,没有任何的交互逻辑,所以啊,现在知道为啥子需要服务端跑一个vue客户端再跑一个vue了,服务端的vue只是混入了个数据渲染了个静态页面,客户端的vue才是去实现交互的!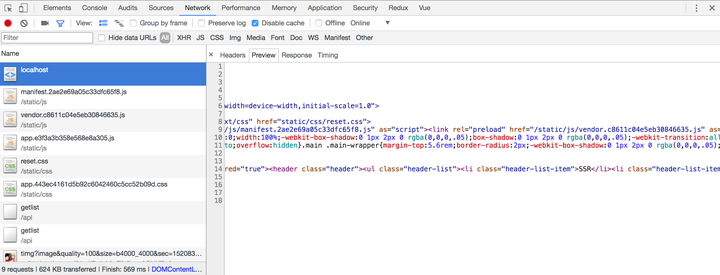
顺着前面的思路,我们该看客户端的entry了。在这里客户端拿到存在window中的数据混入我们客户端的vuex中,然后分析数据去执行我们熟悉的其余客户端操作了。
4.SSR独特之处
在SSR中,创建Vue实例、创建store和创建router都是套了一层工厂函数的,目的就是避免数据的交叉污染。
在服务端只能执行生命周期中的created和beforeCreate,原因是在服务端是无法操纵dom的,所以可想而知其他的周期也就是不能执行的了。
服务端渲染和客户端渲染不同,需要创建两个entry分别跑在服务端和客户端,并且需要webpack对其分别打包;
SSR服务端请求不带cookie,需要手动拿到浏览器的cookie传给服务端的请求。实现方式戳这里。
SSR要求dom结构规范,因为浏览器会自动给HTML添加一些结构比如tbody,但是客户端进行混淆服务端放回的HTML时,不会添加这些标签,导致混淆后的HTML和浏览器渲染的HTML不匹配。
性能问题需要多加关注。
- vue.mixin、axios拦截请求使用不当,会内存泄漏。原因戳这里
- lru-cache向内存中缓存数据,需要合理缓存改动不频繁的资源。
5.可能是把双刃剑
SSR的优点
- 更利于SEO。
不同爬虫工作原理类似,只会爬取源码,不会执行网站的任何脚本(Google除外,据说Googlebot可以运行javaScript)。
使用了Vue或者其它MVVM框架之后,页面大多数DOM元素都是在客户端根据js动态生成,可供爬虫抓取分析的内容大大减少。
另外,浏览器爬虫不会等待我们的数据完成之后再去抓取我们的页面数据。服务端渲染返回给客户端的是已经获取了异步数据并执行JavaScript脚本的最终HTML,网络爬中就可以抓取到完整页面的信息。
- 更利于首屏渲染
首屏的渲染是node发送过来的html字符串,并不依赖于js文件了,这就会使用户更快的看到页面的内容。尤其是针对大型单页应用,打包后文件体积比较大,普通客户端渲染加载所有所需文件时间较长,首页就会有一个很长的白屏等待时间。
6.SSR的局限
服务端压力较大
本来是通过客户端完成渲染,现在统一到服务端node服务去做。尤其是高并发访问的情况,会大量占用服务端CPU资源;开发条件受限
在服务端渲染中,created和beforeCreate之外的生命周期钩子不可用,因此项目引用的第三方的库也不可用其它生命周期钩子,这对引用库的选择产生了很大的限制;学习成本相对较高
除了对webpack、Vue要熟悉,还需要掌握node、Express相关技术。相对于客户端渲染,项目构建、部署过程更加复杂。
6.去除VUEX的SSR实践
先附上demo地址,戳这里!
说在前面:
- vue-router不是必须的,不用router其实做个vue的preRender就可以了,完全没必要做ssr;
- vuex不是必须的,vuex是实现我们客户端和服务端的状态共享的关键,我们可以不使用vuex,但是我们得去实现一套数据预取的逻辑;
官网的demo大而全,集成了vue-router和vuex,想想我们的项目如果没有使用到这两者,光引入就又需要改造成本,这并不是我们想搞的“丝滑般”过渡,接下来笔者将带领大家一步一步的做个“啥都没有的”demo。
在此笔者的思路是:构造一个Vue的实例,那么我们可以用这个实例的data来存储我们的预取数据,而用methods中的方法去做数据的异步获取,这样我们只在需要预取数据的组件中去调用这个方法就可以了。
首先我们需要让我们的组件“共享”这个EventBus,为此笔者简单的封装了一个plugin:
1 | export default { |
然后我们需要在main.js中export出我们的EventBus以便两个entry使用。这样我们的main.js就像下面这样:
1 | import Vue from 'vue' |
接下来是我们的两个entry了。server用来匹配我们的组件并调用组件的asyncData方法去获取数据,client用来将预渲染的数据存储到我们eventBus中的data中。
1 | // server |
然后我们需要改造我们的组件了,只需要定义一个async方法去调用EventBus中的方法获取,考虑到服务端只会执行beforeCreate和created两个生命周期而beforeCreate不能拿到data,所以我们需要在created中去做数据的获取。
1 | // 服务端渲染数据预取; |
然后是webpack的改造了,webpack的配置其实和纯客户端应用类似,为了区分客户端和服务端两个环境我们将配置分为base、client和server三部分,base就是我们的通用基础配置,而client和server分别用来打包我们的客户端和服务端代码。
首先是webpack.server.conf.js,用于生成server bundle来传递给createBundleRenderer函数在node服务器上调用,入口文件是我们的entry-server:
1 | const webpack = require('webpack') |
其次是webpack.client.conf.js,这里我们可以根据官方的配置生成clientManifest,自动推断和注入资源预加载,以及 css 链接 / script 标签到所渲染的 HTML。入口是我们的client-server:
1 | const webpack = require('webpack') |
从localhost中我们看到ssr预取的数据已经成功出来了,大功告成!
7.结语
本文介绍了Vue的SSR的构建和运行流程,也分析了SSR的特点和利弊,希望对大家了解SSR有一定的帮助。最后针对不使用vuex的SSR实现方案进行了介绍,如果感兴趣或者有疑问,欢迎大家留言交流。